
最近自分の作った機械学習モデルがどれだけ仮想通貨の予測に通用するか試すために、ビットコインの自動売買botを作っているふしたくです。
作ったのはいいものの、なかなか思うようにいかず勝率は52%程度を超えられず、「コイントスとほぼ同じやないかい!」という状況から抜け出せていないのが現状です。
そんな中で見つけた以下の本が参考になったので、その本の中で新しい考え方だと感じた部分を紹介します!
ファイナンス機械学習―金融市場分析を変える機械学習アルゴリズムの理論と実践

時間足データの分析は意味があるのか?
ファイナンス機械学習の第2章では、機械学習アルゴリズムの利用に適した金融データの変換方法について詳しく記述されています。
ここで、時間足データとは、ある期間内におけるデータを集計して始値、高値、安値、終値を算出したデータのことです。
このデータは以下の画像のようなローソク足という形で表示されます。
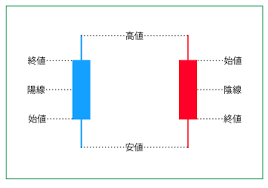
株価チャートに出てくるあれですね。
金融データの分析を行う人が扱うデータは、大抵時間足データ(1分足、1時間足、日足、週足など)を使って分析していますが、この本の2章では、
そのデータで分析するの意味あるの?
ということが述べられています。
このような一定の時間間隔でOHLC(始値、高値、安値、終値)を集計しているデータをタイムバーと呼びます。
ちなみにOHLCは、Open(始値)、High(高値)、Low(安値)、Close(終値)の頭文字をとった用語になります。
タイムバーがダメな2つの理由
ではなぜタイムバーを使ってはいけないのでしょうか。それは以下の2つの理由が挙げられます。
- 時間によってサンプル数が異なる
- 一定時間ごとにサンプリングされた系列は統計的性質が好ましくない
これらについて詳しく解説していきます。
1. 時間によってサンプル数が異なる
例えば、ある日の1分足タイムバーデータから2つ任意に取り出し、それらをタイムバーA,Bとします。そのとき、
- タイムバーAの取引数は5
- タイムバーBの取引数は100
この場合2つの情報量は同じでしょうか?当然変わってきますよね!
取引数が違えば、正しくその時間内の価格のばらつきの影響を反映させることができません。
ビットコインの場合、株式市場のように開いてる時間が決まっておらず世界中誰でも取引できるので、サンプル数の偏りは少ないかと思いますが、株式市場の場合は寄り付き(株式市場が開いた直後)の時などは取引が殺到するため閑散時間との乖離はより大きいものになるでしょう。
2. 一定時間ごとにサンプリングされた系列は統計的性質が好ましくない
これも1.が起因している部分もあるかと思いますが、データごとの情報量が異なれば、系列相関、分散不均一性、非正規分布リターンなどが生まれ分析するのが困難になります。簡単に言えば、望ましい統計的性質を持つっていないということです。
ここでいう望ましい統計的性質とは「それぞれのデータが独立同分布(i.i.d)の正規分布に従うといえる」ということであり、タイムバーではそれが満たされていないということです。
なぜこのような性質が必要かというと、多くの統計手法は観測値が独立同分布の正規分布から生成されると仮定しているため必要となるのです。
じゃあ、どんなバーを作ればいいのか
そこで、これらの問題を解消するために幾つかのバーたちが本書では載っており、
- 「ティックバー」・・・取引数ごとに区切ってOHLCを集計する
- 「ボリュームバー」・・・出来高(株数など)ごとに区切ってOHLCを集計する
- 「ドルバー」・・・売買金額ごとに区切ってOHLCを集計する
があります。(より発展的なバーの紹介もされていますが、ここでは割愛します。)
これらのバーは全て、「膨大な取引データをどれくらいのデータで区切って集計するか」の違いになっており、タイムバーもこの一種に過ぎないということです。
ティックバー
Mandelbrot and Taylorら[1]は、一定の取引数(例:100取引ずつ)で集計してOHLCを計算したデータを作れば、望ましい統計的特性を示すことに初めて気づき、これにより作ったバーをティックバーと呼びます。
これによって、各データは安定したサンプルから集計できるため優れた推論できるとされます。
そのため、1960年代には多くの顧客がこのティック価格に関心があったとされています。
しかし、ティックバーは分割注文に弱いという特性があります。
例えば、次の2パターンを考えてみましょう。ある一人の人物が
- 1つの注文で、100株取引する場合
- 同じ値段で100個の注文を、それぞれ1株のみ取引する場合
これらは情報量が同じですが、前者は1データとしてのみ記録され、後者は100データとして記録されます。
個人でこのように注文する人は少ないかもしれませんが、証券会社の注文システムによっては株数が大きい取引は分割するようにしているところもあります。
ボリュームバー
続いてボリュームバーです。
ボリュームバーはティックバーで発生する問題を解決するために生まれた集計方法です。
これは株などの取引量(出来高、株数)でデータを区切って作成するバーになります。
例えば、1000株ずつで区切れば、例え分割注文されていたとしても同じ情報量で集計が可能になります。
1973年にClark[2]は、ボリュームバーによるデータがティックバーよるデータよりも優れた統計的性質(より独立同分布の正規分布に近い)を示すことを確認しました。
ドルバー
最後にドルバーについてです。
ドルバーは売買金額で区切って作成するバーになります。1取引あたりの売買金額は
売買金額 = ( 1取引における株数 ) × ( その取引における株価 )
で算出されます。
ドルバーは大きな価格変動がある場合では、ティックバーやボリュームバーよりも売買金額でサンプリングしたドルバーの方が良くなるようです。
ちなみに、ドルバーの名前の「ドル」というのはたまたまドルが使われているだけで、必ずしもドルである必要はありません。日本円に換算するなら「円バー」でもいいかと思います!
近似的にボリュームバー、ドルバーを作る
上で紹介したバーは、どれも取引データをどういった基準で区切るかについて述べていました。
ですが、私たち一般人が入手できる金融データはすでにタイムバーになっているデータばかりなので厳密にこれらのバーを作ることはできません。
もしかしたらAPIなどで取得できるかもしれませんが、仮に取得できても全ての取引データを加工することになるため、たった数分だけでもとんでもない計算量が必要なる可能性があり、それをするのは得策ではありません。
そこで、現実的な問題も考慮した上で私たちにできるのは、極力細かいタイムバーのデータをボリュームバー、ドルバーに加工することになります。
(ここで、ティックバーを含めていないのは後述するデータに取引数のデータがなかったためです。)
以下では、そのプログラムの解説をしていきます。
ボリューム、ドルバーへの変換コード
Githubに全コードはまとめて記載してあるので、適宜こちらから参照してください。
使用データとモジュールのインポート
使用するデータはビットコインの1分足データです。
データはKaggleの以下のリンクから入手できます。
Bitcoin Historical Data
から簡単にとってくることができるので、是非ダウンロードしてみてください。
import numpy as np
import pandas as pd
from datetime import datetime
import time
data = pd.read_csv('bitstampUSD_1-min_data_2012-01-01_to_2020-12-31.csv')
display(data.head())
読み込んだ直後の生データはかなり欠損などもあり、加工して、必要な情報だけ残します。
データの前処理、時間足
data['datetime'] = pd.to_datetime(data.Timestamp, unit='s')
data = data.set_index('datetime').drop('Timestamp',axis=1)
data = data.dropna(how='any')['2017':].drop('Weighted_Price',axis=1)
display(data.head())
だいぶ綺麗になりましたね。
ここで、「Volume_(Currency)」は「Volume_(BTC)」をドルで換算したときの値になります。厳密にはそれぞれの取引における値段が影響していますが、大体OHLCの値×Volume(BTC)と一致します。
また、データの観測時間で入っていない部分があります。
 読者
読者これじゃちゃんとボリュームバーを計算できないじゃないか!
という声もあるかと思います。
ですが、これは取引が行われていないということを表しているので、ボリュームバーを作る際には問題ありません。
また、コードでは2017年以降に絞っています。このデータは2011年からのデータが入っていますが、2011~2016までのデータはかなり粒度が粗く、ボリュームバー、ドルバーを作るのに適切ではないと考えたため削っています。
ボリュームバー、ドルバーを作る関数
以下は実際に作成した関数になります。かなり長いので飛ばしてもらって構いません。
簡単に言えば、「上から順にVolumeを足していって、指定した閾値に到達したらそこまでのデータで集計を行いOHLC値を算出し、それをデータフレームにまとめる関数」です。
閾値とは、自身で恣意的に決定する値のことで、ここでは集計するボリュームの値になります。
コードが長くなったのは、各行のVolumeを足し合わせて閾値超えた時、その値を含めた場合と含めなかった場合どちらの方がより閾値に近いかを検証するように作ったためです。
#Volume_barを作成する関数
#入力dfの列は必ず以下の通りの順番にする
#['Open', 'High', 'Low', 'Close', 'Volume_(BTC)', 'Volume_(Currency)']
def create_bar2(df,threshold,bar):
Cum_currency = 0
Cum_BTC = 0
Current_num = 0
Volume_df = pd.DataFrame(columns=df.columns)
progress_i = 0
for index,row in df.iterrows():
#Volumeがリセットされた次の行での処理
if (Cum_currency == 0) | (Cum_BTC == 0) :
open_time = index
open_price = row[0]
high_price = row[1]
low_price = row[2]
#前の行までの累積の値
prev_Cum_currency = Cum_currency
prev_Cum_BTC = Cum_BTC
#今回の行を足し合わせる
Cum_currency += row[5] #Volume_(Currency)
Cum_BTC += row[4] #Volume_(BTC)
# 〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
#足し合わせた結果閾値から遠のいてしまった場合
#前の行までで区切りをつけて、今処理している行を新しい行とする
if (abs(threshold['Currency'] - prev_Cum_currency) < abs(threshold['Currency'] - Cum_currency)) & (bar == 'Currency'):
#区切りをつける
Volume_df.loc[open_time] = [open_price, high_price, low_price, prev_close, prev_Cum_BTC, prev_Cum_currency]
#今回の行を新しい行として処理
Cum_currency = row[5]
Cum_BTC = row[4]
open_time = index
open_price = row[0]
high_price = row[1]
low_price = row[2]
#次の行にとってのprevだからprev_close
prev_close = row[3]
progress_i += 1
continue
if (abs(threshold['BTC'] - prev_Cum_BTC) < abs(threshold['BTC'] - Cum_BTC)) & (bar == 'BTC'):
#区切りをつける
Volume_df.loc[open_time] = [open_price, high_price, low_price, prev_close, prev_Cum_BTC, prev_Cum_currency]
#今回の行を新しい行として処理
Cum_currency = row[5]
Cum_BTC = row[4]
open_time = index
open_price = row[0]
high_price = row[1]
low_price = row[2]
#次の行にとってのprevだからprev_close
prev_close = row[3]
progress_i += 1
continue
# 〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
if row[1] > high_price:
high_price = row[1]
if row[2] < low_price:
low_price = row[2]
prev_close = row[3]
#Volume_barの時
if (Cum_BTC > threshold['BTC']) & (bar == 'BTC'):
close_price = row[3] #close
Volume_df.loc[open_time] = [open_price, high_price, low_price, close_price, Cum_BTC, Cum_currency]
Cum_currency = 0
Cum_BTC = 0
#ドルバーの時
if (Cum_currency > threshold['Currency']) & (bar == 'Currency'):
close_price = row[3] #close
Volume_df.loc[open_time] = [open_price, high_price, low_price, close_price, Cum_BTC, Cum_currency]
Cum_currency = 0
Cum_BTC = 0
progress_i += 1
return Volume_df実際に実行するコードは以下になります。
Thresholdはボリュームバーを作成するための閾値(基準)になります。
BARは’BTC’か’Currency’
BAR = 'BTC' #barは'BTC'か'Currency'を指定できる
Threshold = 200
Volume_df = create_bar2(data,Threshold, bar=BAR)
display(Volume_df.head())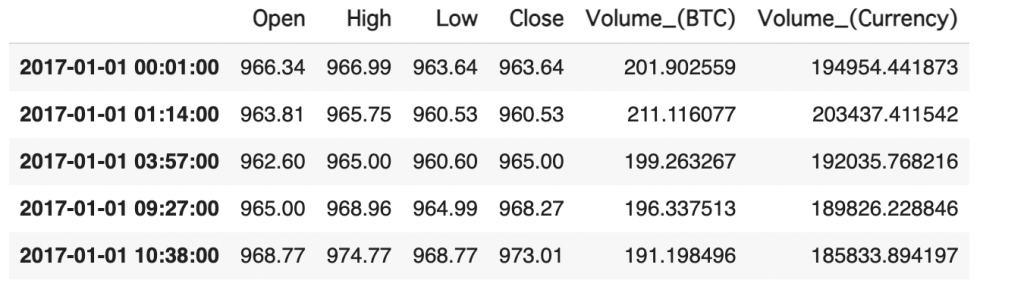
大体200付近で収まっているのが分かりますね!
このデータの統計的性質の検証などはまた別の記事にしようと思います。
まとめ
今回はファイナンス機械学習の第2章を元に、各種バーの解説をし、
その後ボリュームバー、ドルバーを近似的に作る方法を実装しました。
この方法はティックデータを取得できない私たちが極力簡単に実装するために編み出した方法であるので、今後統計的性質に関しては要検証なので、また記事にしてあげたいと思っています!
長文になりましたが、読んでいただきありがとうございました!
参考文献
- Mandelbrot,B.andM.Taylor (1967) : “On the distribution of stock price differences.” OperationsResearch, Vol.15, No.5, pp.1057–1062.
- Clark,P.K.(1973) : “A subordinated stochastic process model with finite variance for speculative prices.” Econometrica, Vol.41, pp.135–155.
- マルコス・ロペス・デ・プラド. ファイナンス機械学習金融市場分析を変える機械学習アルゴリズムの理論と実践 (Japanese Edition)







コメント